旁路缓存的一致性问题
前置知识
旁路缓存的写操作包括:操作数据库和操作缓存两个部分。
故这里的写操作不是原子的。
可能会影响数据一致性的情况:
操作失败问题:因为操作分为两步,那么就很有可能存在「第一步成功、第二步失败」的情况发生。
并发问题:在多线程的情况会有并发问题。
无论是先操作缓存,还是先操作数据库,但凡后者执行失败了,我们就可以发起重试,尽可能地去做「补偿」。
那这是不是意味着,只要执行失败,我们「无脑重试」就可以了呢?
答案是否定的。现实情况往往没有想的这么简单,失败后立即重试的问题在于:
立即重试很大概率「还会失败」
「重试次数」设置多少才合理?
重试会一直「占用」这个线程资源,无法服务其它客户端请求
那更好的方案应该怎么做?
答案是:异步重试。
什么是异步重试?
其实就是把重试请求写到「消息队列」中,然后由专门的消费者来重试,直到成功。
消息队列
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的需求)
Canal:
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
这里写操作具体的方案值得讨论,先操作缓存还是数据库?更新缓存还是删除缓存?
会有四种选择:
1、先更新缓存再更新数据库
2、先更新数据库再更新缓存
3、先删除缓存再更新数据库
4、先更新数据库再删除缓存
1. 先更新缓存,再更新数据库
并发的讨论:
有线程 A 和线程 B 两个线程,需要更新「同一条」数据,会发生这样的场景:
线程 A 更新缓存(X = 1)
线程 B 更新缓存(X = 2)
线程 B 更新数据库(X = 2)
线程 A 更新数据库(X = 1)
最终 X 的值在缓存中是 2,在数据库中是 1,发生不一致。
也就是说,A 虽然先于 B 发生,但 B 操作缓存和数据库的时间,却要比 A 的时间短,执行时序发生「错乱」,最终这条数据结果是不符合预期的。
问题:
- 缓存更新成功,但数据库更新失败:缓存中是新数据,数据库中是旧数据,数据不一致。
- 虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存「失效」,就会从数据库中读取到「旧值」,重建缓存也是这个旧值。这时用户会发现自己之前修改的数据又「变回去」了,对业务造成影响。
- 另外,更新数据库失败的概率(唯一索引冲突、事务超时、事务回滚)要远高于缓存更新失败的概率,容易造成请求实际失败但是脏数据又写入了缓存的尴尬情况。
- 并发时的执行时序问题:缓存中是线程B的值2,数据库中是线程A的值1,数据不一致。
不可取,很容易出现缓存数据库不一致。
2. 先更新数据库,再更新缓存
问题:
- 数据库更新成功,但缓存更新失败:数据库中是新数据,缓存中是旧数据,数据不一致。
- 之后的读请求读到的都是旧数据,只有当缓存「失效」后,才能从数据库中得到正确的值。这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
- 并发时的执行时序问题:数据库中是线程B的值2,缓存中是线程A的值1,数据不一致。
一致性不稳定,不可取。
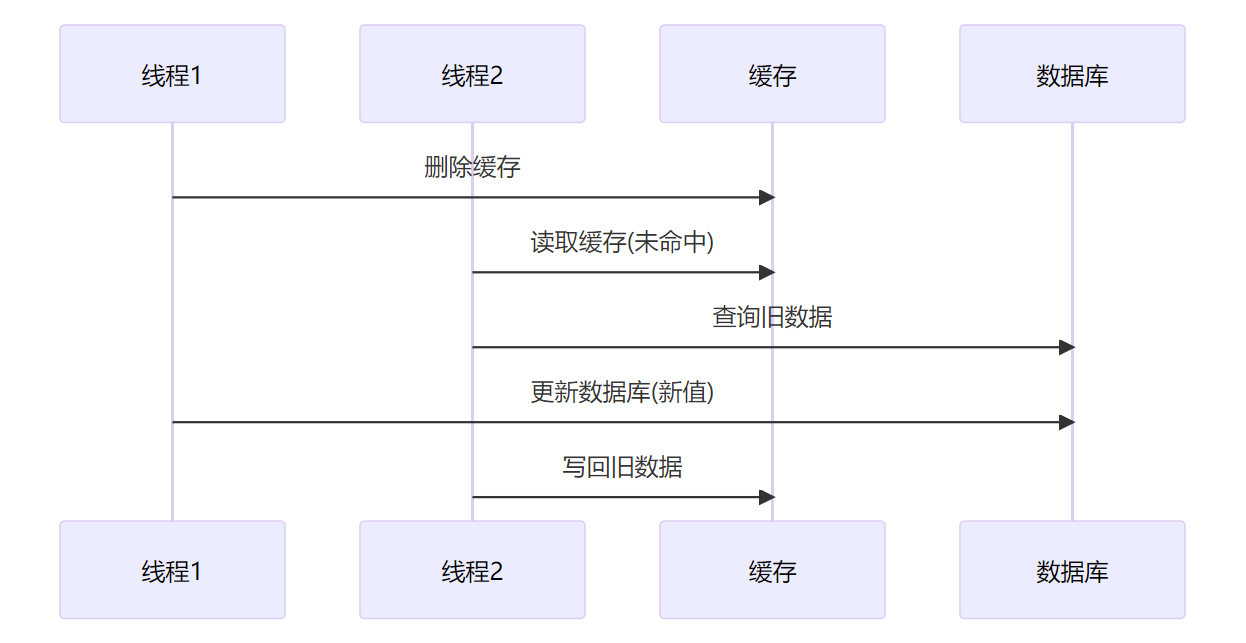
3. 先删除缓存,再更新数据库
并发的讨论:
有 2 个线程要并发「读写」数据,可能会发生以下场景:
线程 A 要更新 X = 2,线程 B 要读取 X。
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
问题:
- 并发问题:当发生「读+写」并发时,可能出现缓存中被更新为旧值,数据库中是新值,数据不一致。
存在严重并发问题,不可取。
4. 先更新数据库,再删除缓存(推荐方案)
并发的讨论:
2 个线程并发「读写」数据:
- 缓存中 X 未命中,线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
但是在实际中,这个问题发生的概率「很低」。
因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现线程 B 已经更新了数据库并且删除了缓存,线程 A 才更新完缓存的情况。
这么来看,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
问题:
- 数据库更新成功,但缓存删除失败:数据库中是最新值,缓存中是旧值,发生不一致。(如果给缓存数据加上了过期时间,则数据过一段时间更新为新值)
这种情况写入数据库删除缓存失败怎么办?
1、可以把两个操作放在一个事务里,如果删除缓存失败,就把写数据库回滚,但是不适合高并发场景,容易出现大事务造成死锁问题。
2、使用重试机制,重试三次,三次都失败就把日志记录到数据库,使用分布式job调度组件做后续删除处理
3、高并发最好使用异步方式重试删除,比如发送消息到MQ中间件,实现异步解耦,或者利用Canal订阅MySQL binlog,监听对应的更新请求,执行删除对应缓存操作。
有两种方案:
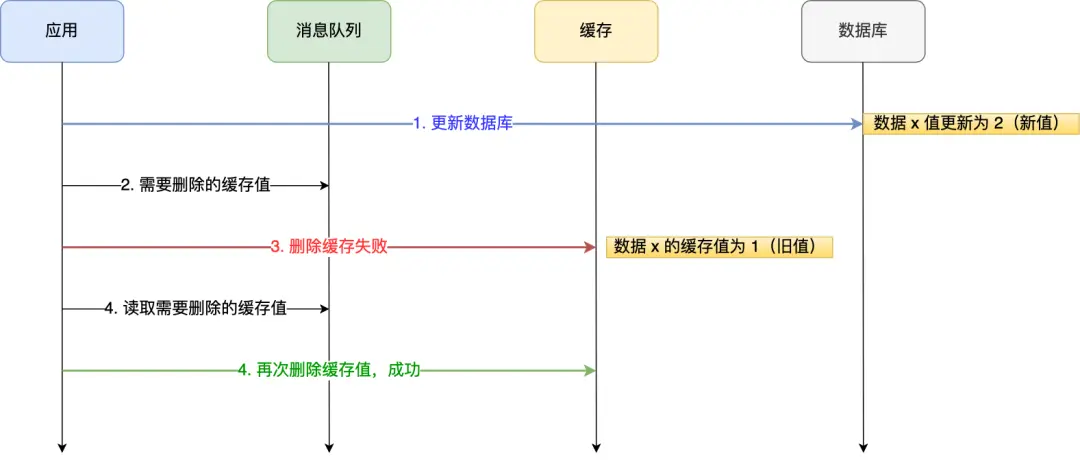
- 方案一:消息队列重试机制。
- 我们可以引入消息队列,将删除缓存时要操作的数据加入到消息队列,由消费者来操作缓存。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
- 缺点:对代码入侵性比较强,因为需要改造原本业务的代码
- 我们可以引入消息队列,将删除缓存时要操作的数据加入到消息队列,由消费者来操作缓存。
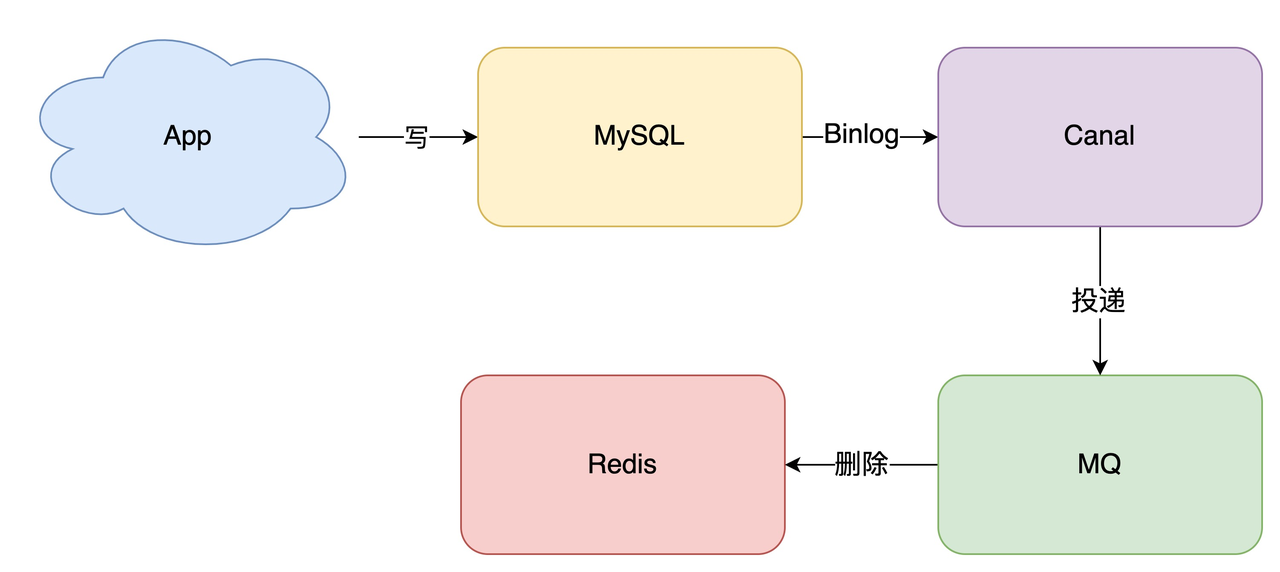
- 方案二:订阅数据库变更日志(MySQL binlog),再操作缓存。
- 我们的业务应用在修改数据时,「只需」修改数据库,无需操作缓存
- 我们可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再根据这条数据,去删除对应的缓存
- 订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal
- 具体的做法是,将 binlog日志采集发送到 MQ 队列里面,然后编写一个简单的缓存删除消息者订阅binlog日志,根据更新log删除缓存,删除缓存成功时通过ACK机制确认处理这条更新log,保证数据缓存一致性
- 优点:
- 无需考虑写消息队列失败情况:只要写 MySQL 成功,Binlog 肯定会有
- 自动投递到下游队列:canal 自动把数据库变更日志「投递」给下游的消息队列
- 与业务代码没有耦合
- 缺点:
- 需要投入精力去维护 canal 的高可用和稳定性
示例:
- 更新数据库,binlog
- 使用flink cdc(阿里的canal不太推荐,听说有坑)订阅binlog日志获取目标数据和key
- 获取flink cdc的数据,解析目标key,尝试删除缓存
- 删除失败则把消息发送给消息队列
- 缓存删除系统从消息队列中重新获取数据,再次执行
如何保证删除缓存成功:异步重试。
补充
「先更新数据库,再更新缓存」方案的数据一致性解决
「先更新数据库,再删除缓存」的方案虽然保证了数据库与缓存的数据一致性,但是每次更新数据的时候,缓存的数据都会被删除,这样会对缓存的命中率带来影响。
所以,如果我们的业务对缓存命中率有很高的要求,我们可以采用「更新数据库 + 更新缓存」的方案,因为更新缓存并不会出现缓存未命中的情况。
如何解决「先更新数据库,再更新缓存」时可能发生数据不一致的情况?
以下有两种方案:
- 方案一:加分布式锁
- 避免了并发问题
- 缺点:会影响性能
- 方案二:在更新完缓存时,给缓存加上较短的过期时间
- 即时出现缓存不一致的情况,缓存的数据也会很快过期,这样对业务还是能接受的。
缓存中被更新「旧值」现象
「读写分离 + 主从复制延迟」情况下,并发的讨论:
如果使用「先更新数据库,再删除缓存」方案,其实也会发生不一致。
- 线程 A 更新主库 X = 2(原值 X = 1)
- 线程 A 删除缓存
- 线程 B 查询缓存,没有命中,查询「从库」得到旧值(从库 X = 1)
- 从库「同步」完成(主从库 X = 2)
- 线程 B 将「旧值」写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在主从库中是 2(新值),也发生不一致。
缓存被回种了「旧值」:
- 现象1:「先删除缓存,再更新数据库」场景中,当发生「读+写」并发时,可能出现缓存中被更新为旧值,数据库中是新值,数据不一致
- 现象2:「读写分离 + 主从复制延迟」情况下,缓存和数据库一致性的问题
如何解决?
方案:缓存延迟双删策略
- 解决第一个问题:在线程 A 删除缓存、更新完数据库之后,先「休眠一会」,再「删除」一次缓存。
- 解决第二个问题:线程 A 可以生成一条「延时消息」,写到消息队列中,消费者延时「删除」缓存。
延时双删
延迟双删又有两种。
1. 删 → 写 → 删
先删缓存,再更新数据库,延迟一段时间再删一次缓存。
可能出现的情况:
在删除缓存和更新数据库之间,读请求可能会访问到旧的数据,再次删除缓存之前的一段时间内读到的都是脏数据。
极端情况下,在删除缓存和更新数据库之间查到旧值的线程,在再删缓存之后才更新到缓存之中,造成后续的请求读缓存和数据库不一致。
缓存本来就是应对高并发的,减轻数据库负担,这种方案数据库没更新,就先把缓存删了。(这点和前面先删缓存,再更新数据库一样)
把多个情况汇总成表格如下:
| 时间轴 | A 线程 | B 线程 | C 线程 | D 线程 |
|---|---|---|---|---|
| t1 | 删除缓存 | |||
| t2 | 查询数据库(旧数据) | 查询数据库(旧数据) | ||
| t3 | 更新数据库 | |||
| t4 | 旧数据放入缓存 | |||
| t5 | 查询数据库(新数据) | |||
| t6 | 新数据放入缓存 | |||
| t7 | 延迟几秒后再次删除缓存 | |||
| t8 | 旧数据放入缓存(极端情况) |
说明:D 线程在 t2 就查到了旧值,但很晚才把旧值写回缓存(t8),这是标注的“极端情况”。
2. 写 → 删 → 删
先更新数据库,再删缓存,延迟一段时间后再删一次缓存。
可能出现的情况:
- 更新数据库后,如果在删除缓存之前有读请求过来,这些请求会读到旧的缓存数据,但最终会被延迟的删除操作清除。(会有一个短暂不一致的时间窗口
- 在删 → 写 → 删下,在第1、2阶段间如果有读请求,都会有短暂的不一致情况,但是,线程2把旧数据写回缓存后,这会持续到第二次删除才清理。所以只要触发这个场景,不管数据库写操作快慢,旧数据都会存在固定的延迟时间。
- 而在写 → 删 → 删下,可能第一次删就把就旧数据删除,也可能第一次删之后一段时间后线程2把旧数据写入,不一定需要等满固定的延迟时间。(不一致窗口不是必然的延迟时间)
- 如果在更新数据库之前缓存过期,D线程、C线程几乎同时读数据库旧数据,D线程回填旧数据,C线程卡住,并在极端情况下在A线程延迟删缓存之后C线程才回填并用旧数据覆盖缓存,后续请求读缓存和数据库不一致,不过这种情况发生概率极低,合理设置延迟时间会让这种情况发生概率更低。
把多个情况汇总成表格如下:
| 时间轴 | A 线程 | B 线程 | C 线程 | D 线程 |
|---|---|---|---|---|
| t1 | 查询数据库(旧数据) | 查询数据库(旧数据) | ||
| t2 | (卡顿,未写缓存) | 旧数据放入缓存 | ||
| t3 | 更新数据库(新值) | |||
| t4 | 查询缓存(旧数据) | |||
| t5 | 删除缓存 | |||
| t6 | 把旧数据放入缓存 | |||
| t7 | 延迟几秒后再次删除缓存 | |||
| t8 | 旧数据放入缓存(极端情况) |
第二种延迟双删(先更新数据库,再删缓存,延迟一段时间后再删一次缓存)在高并发场景下更为安全和可靠。
延迟时间到底设置要多久呢?
这个时间在分布式和高并发场景下,其实是很难评估的。很多时候,我们都是凭借经验大致估算这个延迟时间,例如延迟 1-5s,只能尽可能地降低不一致的概率。极端情况下,还是有可能发生不一致。
延迟时间:建议评估项目读数据业务逻辑耗时,在此基础加上几百毫秒作为延迟时间。
延迟双删比较理论,延迟时间怎么定是个难题。
因此,实际使用中,还是比较建议采用「先更新数据库,再删除缓存」的方案,同时,要尽可能地保证「主从复制」不要有太大延迟,降低出问题的概率。
旁注
实际环境
这篇文章是以「尽可能保证缓存和数据库一致性」这个角度写的,尽可能列出可能遇到的场景、问题、方案优劣。
实际环境为了成本考虑,也可以不用实现得这么复杂,但你需要知道哪块没做到,会有什么问题,并且业务可以容忍这些问题带来的影响,如果不能容忍,文章提供的思路你可以借鉴一下。总之,可以根据场景选择适合自己的方案。
可以做到强一致吗
看到这里你可能会想,这些方案还是不够完美,我就想让缓存和数据库「强一致」,到底能不能做到呢?
其实很难。
要想做到强一致,最常见的方案是 2PC、3PC、Paxos、Raft 这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。
相反,这时我们换个角度思考一下,我们引入缓存的目的是什么?
没错,性能。
一旦我们决定使用缓存,那必然要面临一致性问题。性能和一致性就像天平的两端,无法做到都满足要求。
而且,就拿我们前面讲到的方案来说,当操作数据库和缓存完成之前,只要有其它请求可以进来,都有可能查到「中间状态」的数据。
所以如果非要追求强一致,那必须要求所有更新操作完成之前期间,不能有「任何请求」进来。
虽然我们可以通过加「分布锁」的方式来实现,但我们也要付出相应的代价,甚至很可能会超过引入缓存带来的性能提升。
所以,既然决定使用缓存,就必须容忍「一致性」问题,我们只能尽可能地去降低问题出现的概率。
同时我们也要知道,缓存都是有「失效时间」的,就算在这期间存在短期不一致,我们依旧有失效时间来兜底,这样也能达到最终一致。
小结
操作缓存和数据库时有三个问题需要考虑:
- 删除缓存还是更新缓存:
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多 ×
- 更新缓存会产生无效更新,并且存在较大的线程安全问题
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存 √
- 删除缓存本质是延迟更新,没有无效更新,线程安全问题相对较低
- 如何保证缓存与数据库的操作同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
- 先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库 ×
- 安全问题概率较高
- 先操作数据库,再删除缓存 √
- 在满足原子性的情况下,安全问题概率较低
- 万一发生了 -> 加个超时时间
先删数据库,再删缓存是旁路缓存比较主流的方案,一致性会较好。
给缓存加 TTL是非常必要,即使发生不一致,也能靠过期自动修复。
结论:要保证数据库和缓存一致性,推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来做。
更新缓存与删除缓存的对比:
删除一个数据,相比更新一个数据更加轻量级,出问题的概率更小。
- 更新缓存的成本很高,可能需要访问多张表联合计算。
- 不是所有的缓存数据都是频繁访问的,更新后的缓存可能会长时间不被访问
所以说,从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个思想叫 Lazy Loading,适用于那些加载代价大的操作。
删除缓存而不是更新缓存,就是懒加载思想的一个应用。
总结
- 想要提高应用的性能,可以引入「缓存」来解决
- 引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:「更新数据库 + 更新缓存」、「更新数据库 + 删除缓存」
- 更新数据库 + 更新缓存方案,在「并发」场景下无法保证缓存和数据一致性,解决方案是加「分布锁」,但这种方案存在「缓存资源浪费」和「机器性能浪费」的情况
- 采用「先删除缓存,再更新数据库」方案,在「并发」场景下依旧有不一致问题,解决方案是「延迟双删」,但这个延迟时间很难评估
- 采用「先更新数据库,再删除缓存」方案,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志」的方案来做,本质是通过「重试」的方式保证数据最终一致
- 采用「先更新数据库,再删除缓存」方案,「读写分离 + 主从库延迟」也会导致缓存和数据库不一致,缓解此问题的方案是「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率
一致性问题的一些心得:
性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题
失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案
订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致
参考链接
- http://kaito-kidd.com/2021/09/08/how-to-keep-cache-and-consistency-of-db/
- https://www.xiaolincoding.com/redis/architecture/mysql_redis_consistency.html
- 缓存更新策略和相应的数据一致性问题和方案.md